쿠버네티스에서 Pod 생성을 요청 했을 때, 적당한 node에 배치하는 것을 스케쥴링이라고 한다. 이때 쿠버네티스 스케줄러는 아래 내용을 살펴보고 Pod가 배포될 수 있는 Node를 선정하는 작업을 하게된다.
- 충분한 리소스가 있는가?
- 디스크 볼륨을 사용할 경우 node에서 접근이 가능한가?
- HA 구성을 위해 다른 node, 다른 rack, 다른 zone에 배포 가능한가?
- 기타..
Resource
충분한 리소스가 있는지 없는지 판단하기 위해서는 기준이 있어야한다. 컨테이너에 대해서 리소스 정의를 할 수 있고, 이 정의된 리소스를 기준으로 Node에 충분한 리소스가 있는지 판단할 수 있는 것이다.
# Requests, limits
If the node where a Pod is running has enough of a resource available, it's possible (and allowed) for a container to use more resource than its request for that resource specifies. However, a container is not allowed to use more than its resource limit.
For example, if you set a memory request of 256 MiB for a container, and that container is in a Pod scheduled to a Node with 8GiB of memory and no other Pods, then the container can try to use more RAM.
If you set a memory limit of 4GiB for that Container, the kubelet (and container runtime) enforce the limit. The runtime prevents the container from using more than the configured resource limit. For example: when a process in the container tries to consume more than the allowed amount of memory, the system kernel terminates the process that attempted the allocation, with an out of memory (OOM) error.
Limits can be implemented either reactively (the system intervenes once it sees a violation) or by enforcement (the system prevents the container from ever exceeding the limit). Different runtimes can have different ways to implement the same restrictions.
Note: If a Container specifies its own memory limit, but does not specify a memory request, Kubernetes automatically assigns a memory request that matches the limit. Similarly, if a Container specifies its own CPU limit, but does not specify a CPU request, Kubernetes automatically assigns a CPU request that matches the limit.
# Pod resource
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 8080
resources:
requests:
memory: "1Gi"
cpu: 1
limits:
memory: "2Gi"
cpu: 2# Resource Quota
A resource quota, defined by a ResourceQuota object, provides constraints that limit aggregate resource consumption per namespace. It can limit the quantity of objects that can be created in a namespace by type, as well as the total amount of compute resources that may be consumed by resources in that namespace.
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
spec:
hard:
pods: "10"
requests.cpu: "4"
requests.memory: 5Gi
limits.cpu: "10"
limits.memory:
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["high"]apiVersion: v1
kind: Pod
metadata:
name: high-priority
spec:
containers:
- name: high-priority
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
resources:
requests:
memory: "10Gi"
cpu: "500m"
limits:
memory: "10Gi"
cpu: "500m"
priorityClassName: high| Resource Name | Description |
| pods | The total number of Pods in a non-terminal state that can exist in the namespace. A pod is in a terminal state if .status.phase in (Failed, Succeeded) is true. |
| limits.cpu | Across all pods in a non-terminal state, the sum of CPU limits cannot exceed this value. |
| limits.memory | Across all pods in a non-terminal state, the sum of memory limits cannot exceed this value. |
| requests.cpu | Across all pods in a non-terminal state, the sum of CPU requests cannot exceed this value. |
| requests.memory | Across all pods in a non-terminal state, the sum of memory requests cannot exceed this value. |
| cpu | Same as requests.cpu |
| memory | Same as requests.memory |
- kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 4
memory 0 5Gi
pods 0 10
# Limit Range
By default, containers run with unbounded compute resources on a Kubernetes cluster. With resource quotas, cluster administrators can restrict resource consumption and creation on a namespace basis. Within a namespace, a Pod or Container can consume as much CPU and memory as defined by the namespace's resource quota. There is a concern that one Pod or Container could monopolize all available resources. A LimitRange is a policy to constrain resource allocations (to Pods or Containers) in a namespace.
A LimitRange provides constraints that can:
- Enforce minimum and maximum compute resources usage per Pod or Container in a namespace.
- Enforce minimum and maximum storage request per PersistentVolumeClaim in a namespace.
- Enforce a ratio between request and limit for a resource in a namespace.
- Set default request/limit for compute resources in a namespace and automatically inject them to Containers at runtime.
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: ContainerapiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- default:
cpu: 1
defaultRequest:
cpu: 0.5
type: Container고급 스케줄링 정책
Pod를 배포할 때, 특정 Node를 선택할 수 있도록 정의할 수 있다. 예를 들어 Redis master와 slave들이 같은 Node에 배포되지 않도록 Pod의 스케줄링 정책을 인위적으로 조정할 수 있다. 즉, taint/toleration과 affinity with NodeSelector의 조합으로 특정 노드에 특정 포드가 스케줄링 되도록 할 수 있다.
# Taint/Toleration
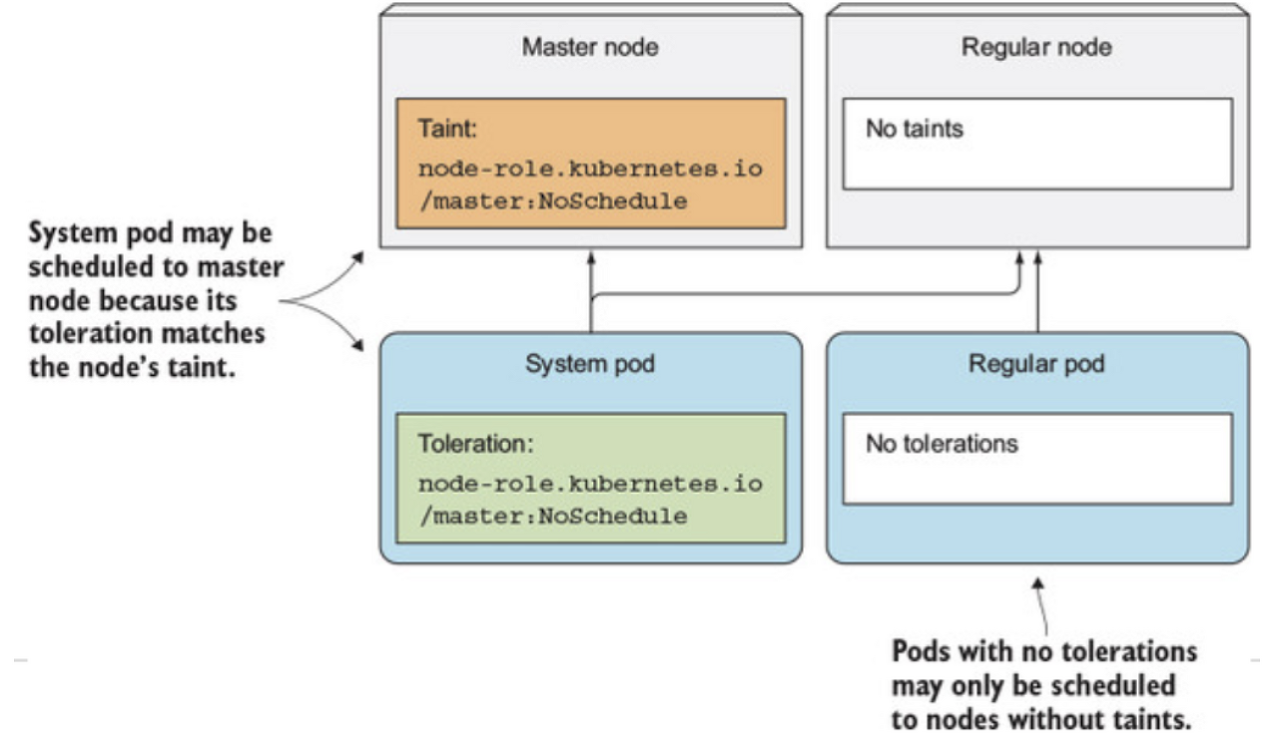
Taints
Taint는 Node에 정의할 수 있고, Toleration은 Pod에 정의할 수 있다.
- Taints & Tolerations does not tell the part to go to a particular node.
- It tells the node to only accept parts with certain toleration
Taint는 특정 Node에 일반적인 pod가 배포되는 것을 막을 수 있다. 즉, 알맞은 toleration을 가지고 있는 Pod만 배포될 수 있다.
Taint Effect
Taint에 적용할 수 있는 effect는 아래와 같이 3가지가 있다.
- NoSchedule : if there is at least one un-ignored taint with effect NoSchedule then Kubernetes will not schedule the pod onto that node(기존에 노드에 머물러 있던 Pod는 그대로 stay!)
- PreferNoSchedule : if there is no un-ignored taint with effect NoSchedule but there is at least one un-ignored taint with effect PreferNoSchedule then Kubernetes will try to not schedule the pod onto the node. the system will try to avoid placing a pod that does not tolerate the taint on the node, but it is not required.
- NoExecute : if there is at least one un-ignored taint with effect NoExecute then the pod will be evicted from the node (if it is already running on the node), and will not be scheduled onto the node (if it is not yet running on the node). a toleration with NoExecute effect can specify an optional tolerationSeconds field that dictates how long the pod will stay bound to the node after the taint is added. pods that tolerate the taint without specifying tolerationSeconds in their toleration specification remain bound forever(돌고 있던 Pod도 evit하고, 다른 node로 옮긴다.)
NoExecute > NoSchedule > PreferNoSchedule 순으로 Pod에 영향을 많이 준다.
# Taint on Nodes
kubectl taint nodes node01 spray=mortein:NoSchedule
kubectl describe nodes node-1 | grep -i taint
# taint 제거
kubectl taint node master/controlplane node-role.kubernetes.io/master:NoSchedule-
kubectl explain pod --recursive | grep -A5 tolerations
# NoSchedule / PreferNoSchedule / NoExecute(killed)Toleration
Taint 처리가 되어있는 Node에 Pod를 배포하기 위해서는 Toleration을 사용해야한다. 일종의 입장권이라고 생각하면 편할 것 같다. 다만 주의해야될 점은 배포되는 것이아니라 배포될 수 있다라는 점이다. 즉, 다른 조건에 맞는 Node가 있다면 해당 Node에 배포될 수도있다.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 8080
nodeSelector:
size: Large # node labeling first!
tolerations:
- key: app
operator: "Equal" / "Exists"
value: "blue"
effect: "NoSchedule"
# Affinity
Taint가 Pod가 배포되지 못하도록 하는 정책이라면, affinity는 Pod가 특정 노드로 배포되도록 하는 기능이다. affinity는 Node를 기준으로 하는 Node affinity와 다른 Pod가 배포된 노드를 기준으로 하는 Pod affinity가 있다.
Node Affinity
Node affinity는 Hard affinity와 soft affinity가 있다.
- Hard affinity는 조건이 딱 맞는 node에만 pod를 배포하는 기능을 하고(node selector와 같은 기능을 한다.) 예를들면, node selector
- Soft affinity는 Pod가 조건에 맞는 node에 되도록이면 배포되도록 하는 기능이다
Node Affinity Types
Node Affinity에 적용할 수 있는 effect는 아래와 같이 2가지가 있다.
- requiredDuringSchedulingIgnoredDuringExecution(hard) : similar to nodeSelector but using a more expressive syntax. If labels on a node change at runtime such that the affinity rules on a pod are no longer met, the pod continues to run on the node.
- preferredDuringSchedulingIgnoredDuringExecution(soft), not guaranteed
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 8080
# schedule a Pod using required node affinity
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: In #NotIn, Exists
values:
- Large
tolerations:
- key: app
operator: "Equal"
value: "blue"
effect: "NoSchedule"Pod affinity
Pod Affinity Types
Pod Affinity에 적용할 수 있는 effect는 아래와 같이 2가지가 있다.
- requiredDuringSchedulingIgnoredDuringExecution(hard) : similar to nodeSelector but using a more expressive syntax. If labels on a node change at runtime such that the affinity rules on a pod are no longer met, the pod continues to run on the node.
- preferredDuringSchedulingIgnoredDuringExecution(soft), not guaranteed
예시는 아래와 같다.
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
클러스터 구성을 할때 1개의 노드에 모든 파드가 배포되었다고 가정해보자. 노드가 갑자기 이상상황이 발생하여 정상 작동하지 않는다면 더이상 서비스를 제공할 수 없을 것이다. 이런 경우에 Pod anti-affinity를 활용할 수 있다.
예를 들어 Redis Cluster 구성한다고 가정해보자. 쿠버네티스 노드가 6개 이상이고, Redis cluster에 필요한 Pod도 6개라고 할때 노드마다 1개의 Redis Pod가 배치된다면 HA 구성을 할 수 있다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster
labels:
app: redis-cluster
spec:
selector:
matchLabels:
app: redis-cluster
serviceName: redis-cluster
replicas: 6
template:
metadata:
labels:
app: redis-cluster
annotations:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- redis-cluster
topologyKey: "kubernetes.io/hostname"
...
Multiple Scheduler
# Scheduler
static pod로 배포된다. 따라서 포드명은 kube-scheduler-{node_name} 다음과 같은 형식이다.
apiVersion: v1
kind: Pod
metadata:
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
image: k8s.gcr.io/kube-scheduler-amd64:v1.11.3
name: kube-scheduler# Custom Scheduler
--learder-elect=false를 이용하여 기존 leader를 유지
--lock-object-name=my-custom-scheduler을 이용하여 새로운 스케줄러가 leader eletion 중에 default가 되는 것을 막음
apiVersion: v1
kind: Pod
metadata:
name: my-custom-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=false (for single master node)
- --scheduler-name=my-custom-scheduler
- --lock-object-name=my-custom-scheduler (for multiple master nodes)
image: k8s.gcr.io/kube-scheduler-amd64:v1.11.3
name: kube-schedulerapiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
schedulerName: my-custom-scheduler
참고
- container resource default : 1 cpu, 512 Mi
1 cpu
- 1 AWS vCPU
- 1 GCP core
- 1 Azure core
- 1 Hyperthread
1 Gi(Gibibyte) like 1 G
1 Mi(Mebibyte) like 1 M
1 Ki(Kibibyte) like 1 K
- The status 'OOMKilled' indicates that the pod ran out of memory.
- debugging
kubectl get events
kubectl logs my-custom-scheduler -n=kube-system
kubectl pod kube-scheduler-master -n kube-system | grep Image
cd /etc/kubernetes/manifests# 노드 테인트 정보가져오기
kubectl describe node kubemaster | grep -i taint
# 노드 라벨링(Node selector와 연동!)
kubectl label nodes node01 size=Large
kubectl label nodes node01 color=blue
# 노드 with label
kubectl get nodes node01 --show-labelsapiVersion: v1
kind: Binding
metadata:
name: nginx
target:
apiVersion: v1
kind: Node
name: node02
출처
- https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- https://thenewstack.io/implementing-advanced-scheduling-techniques-with-kubernetes/
- https://bcho.tistory.com/1344?category=731548
- https://bcho.tistory.com/1346?category=731548
'클라우드 컴퓨팅 > 쿠버네티스' 카테고리의 다른 글
| docker 리소스 제한 (0) | 2021.09.05 |
|---|---|
| docker 기본 (0) | 2021.09.05 |
| Kubernetes Workloads (0) | 2021.08.08 |
| Kubernetes JSONPATH 사용법 (0) | 2021.08.08 |
| Kubernetes Network Model & Policy (0) | 2021.07.08 |